模块和包
模块和包
模块(module)和 包(package)是 Python 用于组织大型程序的利器。
模块 是一个由 变量、函数、类 等基本元素组成的功能单元,设计良好的模块通常是高内聚、低耦合、可复用、易维护的。包 是管理模块的容器,它具有 可嵌套性:一个包可以包含模块和其他包。从文件系统的视角来看,包就是目录,模块就是文件。
从本质上讲,一个模块就是一个独立的名字空间(namespace),单纯的多个模块只能构成扁平结构的名字空间集;而包的可嵌套性,使得多个模块可以呈现出多层次结构的名字空间树。
关于命名空间,请看《命名空间和作用域.md》
模块 - module
模块是一个包含所有你定义的变量、函数和类以及可执行代码的文件,文件名就是模块名,其后缀名是 .py。
模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
还可以重命名,有的时候,模块名太长,写起来不方便或者记不住,我们可以将其重命名为一个好记好写的名字
import module1 [as name1], module2 [as name2],
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
关于什么是解释器,请看《基本概念.md》
不管你对同一个路径执行了多少次 import,一个模块只会被导入一次,这样可以防止导入模块被一遍又一遍地执行。
当我们使用 import 语句的时候,Python 解释器是怎样找到对应的文件的呢?这就涉及到 Python 的搜索路径(sys.path),搜索路径是由一系列目录名组成的,Python 解释器就依次从这些目录中去寻找所引入的模块。这看起来很像环境变量,事实上,也可以通过定义环境变量 PYTHONPATH 的方式来确定搜索路径。搜索路径是在 Python 编译或安装的时候确定的,安装新的库也会自动更新。
搜索路径是一个解释器会先进行搜索的所有目录的列表。
关于什么是 Python 解释器的搜索路径,请看《Python 标准库 -sys 模块.md》中的
模块内容小节的path部分Python 解释器的搜索路径有点类似于 Java 的类路径,而 Python 中的 import 语句的意义则跟 Java 中的 import 语句的意义几乎一模一样
通过 import module_name 这样的语句并没有把直接定义在 module_name 模块中的变量、函数或者类添加到当前模块的符号表里,只是把模块 module_name 的名字添加到了当前模块中,我们需要通过 module_name.var_name、module_name.func_name、module_name.class_name() 调用引入的模块里面的变量和方法和创建引入的模块中的类的实例。
关于当前模块的符号列表,请看
模块中的符号列表小节
在学习了包之后,我们就会知道 module_name 中一般都会带有包路径,比如 module_name 可能为
aaa.bbb.test,而不仅仅是一个test使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
但是实际上在 import 某一个模块的时候,即使模块没有处于包内,也就是说
aaa并不必须是一个包,其实也不会报错,也能正常引用到,只要求按照sys.path中保存的搜索路径加上 import 后面写的路径能够找到导入的模块文件即可。
简单实践:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
test_target.py
aaa = "xiashuo"
_bb = "baidu.com"
def test_info():
print("Hello, bro shu")
class Test_Import():
pass
在另一个文件引入:
import test_target
print(test_target.aaa)
test_target.test_info()
test_obj = test_target.Test_Import()
输出:
xiashuo
Hello, bro shu
有一点点麻烦,接下来我们试试更好用的方法
from import
from 语句让你从模块中导入一个指定的部分到当前命名空间中:
from modname import name1[, name2[, ... nameN]]
也可以重命名,有的时候,属性名、方法名、类名太长,写起来不方便或者记不住,我们可以将其重命名为一个好记好写的名字
from module import attribute [as name]
在 Java 中,也存在部分导入,我们可以通过
import static的方式来静态地导入一个类中的一些静态变量或者一些方法请看《Java 核心技术卷一 _ 第 4 章 _ 对象与类.docx》中地
静态导入小节
简单实践:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
from test_target import aaa,test_info,Test_Import
print(aaa)
test_info()
test_obj_2 = Test_Import()
利用 * 把一个模块的所有内容全都导入到当前的命名空间也是可行的
from modname import *
但是一般不建议这样用,因为此时,Python 不会导入带有单个前置下划线的名称(除非模块定义了覆盖此行为的 __all__ 列表),而且,使用了通配符,导致当前名称空间中存在哪些名称不清楚。为了清楚起见,坚持常规导入更好。
简单实践:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
from test_target import *
# from test_target import _bb
# NameError: name '_bb' is not defined
# print(_bb)
除非,在 test_target.py 中添加对 __all__ 变量的定义,并在其中包含带有单个前置下划线的名称。
aaa = "xiashuo"
_bb = "baidu.com"
def test_info():
print("Hello, bro shu")
class Test_Import():
pass
__all__ = ["aaa", "_bb", "test_info", "Test_Import"]
然后,我们通过 from test_target import * 引入 import 的时候,就只会导入 __all__ 列表中的名字。
from test_target import *
print(_bb)
print(aaa)
test_info()
test_obj_2 = Test_Import()
输出:
baidu.com
xiashuo
Hello, bro shu
模块中的可执行代码
模块也是一个对象,并且模块这个对象有很多默认属性,比如
__name__、__all__、__file__等,具体的请看模块属性小节
模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。
当我们直接运行 python xxx.py 的时候,模块中的可执行代码会执行,此时,__name__ 属性地值为 __main__,而当我们在别的模块中引入这个模块的时候,这个模块中的可执行代码也会运行(注意只有在第一次被导入时才会被执行),此时在这个被导入的模块中地代码执行的时候,在这个模块中,__name__ 属性地值为模块的名称,
因此,如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用 __name__ 属性的值来判断。
简单实践如下:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
test_name.py:
在 Pycharm 中,我们可以通过输入
main来快速输入if __name__ == '__main__':,然后编辑器左侧会出现代表 Run 的三角图标,这个跟 Java 的类中通过输入 psvm 快速生成的的 main 方法的效果一样。
# run_flag 为1 表示正在自我执行,run_flag 为2 表示正在被引入执行,
run_flag = 0
if __name__ == "__main__":
run_flag = 1
print("i am running by myself")
else:
run_flag = 2
print("i am imported")
if run_flag == 1:
print("don't want to work , want to lie down")
else:
print("so great to work here")
直接运行,输出
i am running by myself
don't want to work , want to lie down
在 test_name_import.py 中引入 test_name.py
import test_name
print("start")
执行,输出
i am imported
so great to work here
start
可以注意到 test_name 模块本身的可执行代码在引入了 test_name 模块的模块的可执行代码之前运行。
模块属性
模块中的变量就是模块的属性,同时模块还有一些默认的属性
从把模块中的变量称为模块的属性可以看出,模块其实也是一个对象
默认属性都可以通过
dir()观察到
默认属性:
__builtins__内建名字空间(参考 名字空间)__file__文件名(对于被导入的模块,文件名为绝对路径格式;对于直接执行的模块,文件名为相对路径格式)__name__模块名(对于被导入的模块,模块名为去掉“路径前缀”和“.pyc 后缀”后的文件名,即os.path.splitext(os.path.basename(__file__))[0];对于直接执行的模块,模块名为__main__)__doc__文档字符串(即模块中在所有语句之前第一个未赋值的字符串)__package__包名(主要用于相对导入,请参考 PEP 366)
模块中的符号列表
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。
通过
dir(),我们可以很方便地查看当前作用域内的所有符号/名称,在模块中,这个模块的内部就是一个作用域,所以通过dir()可以看到模块的所有符号/名称,具体请看《命名空间和作用域.md》的作用域小节具体分析请看
dir()小节。
-
当我们使用
import module_name这样的方式导入模块的时候,被导入的模块的名称将被放入当前操作的模块的符号表中。dir() 方法的结果只会增加模块名这一个名称 -
当我们使用
from module_name import var1,func1,class1这样的方式导入模块的时候,import关键字后面的名称将被放入当前操作的模块的符号表中。dir() 方法的结果会增加 var1,func1,class1
如果因为引入的模块而引入的符号跟当前模块中的符号相同,则引入之后,符号原来的含义会被覆盖,这里的覆盖有两种含义,
-
变量值覆盖,比如模块中有一个变量名为
name值为ali,引入的一个模块中也有变量名为name,值为baidu,那么引入模块之后(import 语句之后),name的值为baidu。 -
变量类型改变,比如模块中有一个变量名为
info值为hello world,引入的一个模块中也有变量名为info,是一个方法,那么引入模块之后(import 语句之后),info会变成一个方法`。
动态语言,就是这样的,变量可以为值,也可以为方法
还有一种情况是,先后引入两个模块,且引入的名称存在同名,也是后引入的覆盖先引入的
为了避免名称覆盖,我们可以在引入模块或者引入模块内的名称的时候对其进行重命名
相对而言,第二种 import 方式发生覆盖概率会比较低,因为只引入而来一个符号(这种方式是比较按安全的,不会出现覆盖)
import module_name as module_name1
from module_name import var1 as var2,func1 as func2, class1 as class2
简单实践如下:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
被导入模块 test_target.py
aaa = "xiashuo"
_bb = "baidu.com"
def test_info():
print("Hello, bro shu")
class Test_Import():
pass
__all__ = ["aaa", "_bb", "test_info", "Test_Import"]
主模块
# 冲突变量
aaa = "aliyun"
test_info = "tencent"
print(dir())
print(aaa)
print(test_info)
from test_target import *
# 重命名的写法
# from test_target import aaa as aaa1,test_info as test_info2
print(dir())
# 第一种覆盖
# xiashuo
print(aaa)
# 第二种覆盖
# <function test_info at 0x00000211B7E6A320>
print(test_info)
输出:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'aaa', 'test_info']
aliyun
tencent
i am imported
['Test_Import', '__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_bb', 'aaa', 'test_info']
xiashuo
<function test_info at 0x0000025119B28C10>
当我们使用重命名的写法的时候
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'aaa', 'test_info']
aliyun
tencent
i am imported
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'aaa', 'aaa1', 'test_info', 'test_info2']
aliyun
tencent
dir()
方法注释如下:
如果不带参数调用 dir(),则返回当前作用域中的所有名称。
具体什么是作用域,请看《命名空间和作用域.md》的
作用域小节
如果传入了参数(对象,对象可以是模块,可以是类对象,可以是数字和字符串,数据容器),则返回一个按字母顺序排列的名称列表,该列表包含给定对象的 (部分) 属性(定义在该对象所在的类型中的属性),以及可从该对象获得的属性(该对象的父类的属性)。
实际上
dir()方法调用的就是对象的__dir__方法
-
如果该对象提供了一个名为
__dir__的方法,它将被使用并返回其结果; -
如果该对象没有提供名为
__dir__的方法,则使用默认的dir()逻辑并返回结果,默认的dir()逻辑是:-
对于类对象: 它的属性,以及递归地它的父类的属性。
-
对于任何其他对象: 它的属性,它所在的类的属性,以及递归地它的类的基类的属性。
-
对于模块对象(也就是说传入的是一个模块名称): 模块属性(即模块中的变量)。
-
因为 dir() 主要是为了方便在交互式提示符中使用而提供的,所以它试图提供一组有趣的名称,而不是试图提供严格或一致定义的名称集,并且它的详细行为可能会在不同的版本中发生变化。例如,当参数是一个类时,元类属性不在结果列表中。
简单实践如下:
为了方便处理,所有的模块都处在同一个文件夹/包下,这样 module_name 就不用包含包路径,方便理解模块的定义
被导入模块 test_target.py
aaa = "xiashuo"
_bb = "baidu.com"
def test_info():
print("Hello, bro shu")
class Test_Import():
pass
__all__ = ["aaa", "_bb", "test_info", "Test_Import"]
dir 方法测试模块
import test_target
# 模块对象
print(dir(test_target))
class dir_test():
def __init__(self):
self.name = 'test'
self.age = 12
# def __dir__(self):
# return ['222']
class_ojb = dir_test()
print(dir(class_ojb))
# 数字对象
print(dir(12))
# 字符串对象
print(dir("xiashuo.xyz"))
输出
i am imported
['Test_Import', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_bb', 'aaa', 'run_flag', 'test_info']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name']
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
如果我们在模块中定义了 __dir__ 方法,或者在类中定义了 __dir__ 方法
aaa = "xiashuo"
_bb = "baidu.com"
def test_info():
print("Hello, bro shu")
class Test_Import():
pass
__all__ = ["aaa", "_bb", "test_info", "Test_Import"]
def __dir__():
return ["111"]
class dir_test():
def __init__(self):
self.name = 'test'
self.age = 12
def __dir__(self):
return ['222']
再次输出,会发现模块对象和类对象的 dir() 方法输出变成了定义的 __dir__ 方法的输出
i am imported
['111']
['222']
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
包 - package
包是一种管理 Python 模块命名空间的形式,采用 ".module_name" 的格式。比如一个模块的名称是 A.B, 那么他表示一个包 A 中的子模块 B 。就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用 .module_name 这种形式也不用担心不同库之间的模块重名的情况。这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。
包最主要的功能还是在模块非常多的时候对模块文件进行梳理,分门别类放到不同的包下面,就跟 Java 的包的功能一样
在导入一个路径包含着包名的模块的时候,Python 会以 sys.path 中的搜索目录为起点来按照 import 后的路径或者 from import 中 from 后面的路径来寻找这个包路径下的模块。
关于
sys.path的分析请看《Python 标准库 -sys 模块.md》中的模块内容小节的path部分
sys.path搜索路径一般都包含 Pycharm 中的项目的根路径,所以,我们一般都是直接从 Pycharm 的项目根路径开始创建包
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,否则就是一个普通文件夹,这样要求主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。最简单的情况,放一个空的 __init__.py 在包目录下即可。当然这个文件中也可以包含一些初始化代码或者为 __all__ 变量赋值。
在 Pycharm 中的 Project Tool Windos 中,随意右键一层目录,new 菜单中,有一个专门的菜单叫 Python Package,通过输入
.来分割多级包路径,每一级包下都会默认创建一个__init__.py文件,非常方便,
在 Java 中,包和普通文件夹是没有区别的,在 Python 中,包含
__init__.py文件的文件夹才是包,否则就只是普通文件夹
__init__.py这个脚本会在导入这个这包的时候被调用,这就可以让我们在当前包被导入之前做一点准备工作,比如初始化设置等等,这一点,比 Java 好,多少算是加了一点自定义点
关于
__all__变量的使用,在本小节下的import语句中会进行解释
当一个模块在多层包路径下的时候,每一个层包目录下都应该有一个 __init__.py 文件,而当我们导入 aaa.bbb.ccc.xiashuo 这个模块的时候,aaa、bbb、ccc 这基层路径的 __init__.py 会被依次调用。
简单实践一下,假设包的目录结构是这样的
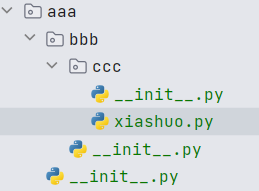
而且 aaa 目录下的 __init__.py 文件内容是 print("aaa imported"),bbb 目录下的 __init__.py 文件内容是 print("bbb imported"),ccc 目录下的 __init__.py 文件内容是 print("ccc imported"),xiashuo.py 的内容是:
if __name__ == '__main__':
print("i am xiashuo")
else:
print("i am imported")
最终当我引用 xiashuo 这个模块的时候
import aaa.bbb.ccc.xiashuo
print("started")
运行,输出
aaa imported
bbb imported
ccc imported
i am imported
started
import / from import
在引入了包的概念之后,import 或者 from import 的语句其实也没有什么变化,可能唯一需要注意的是,在 模块 小节,我们引入的模块都跟最终运行的模块在同一个目录下,所以不需要指定包路径,直接引入模块名,现在我们可以在模块中引入任意路径下的模块,只需要指定完整的包路径即可。
但是有一种需要专门说明,即,import 后面的路径最终指向的是一个包,而不是一个模块,比如有一个模块的完整名称是 aaa.bbb.ccc.xiashuo,正常情况下,我们会 import aaa.bbb.ccc.xiashuo 或者 from aaa.bbb.ccc import xiashuo 来引入这个模块,那如果我只引入包呢?即:import aaa.bbb.ccc 或者 from aaa.bbb import ccc
如果在同一个目录下,存在两个同名的包和模块,那么导入时只会识别包,而忽略模块
我们来简单实践一下:
还是这个包结构:
aaa 目录下的 __init__.py 文件内容是
print("aaa imported")
__all__ = ["bbb"]
bbb 目录下的 __init__.py 文件内容是
print("bbb imported")
__all__ = ["ccc"]
ccc 目录下的 __init__.py 文件内容是
print("ccc imported")
__all__ = ["xiashuo"]
name = 'ccc package'
xiashuo.py 的内容
if __name__ == '__main__':
print("i am xiashuo")
else:
print("i am imported")
name = "xiashuo"
age = 12
def info():
print(f"{name},{age}")
class xia_shuo():
def __init__(self):
print("xiashuo constructed")
此时,我们在一模块中引用 aaa.bbb.ccc.xiashuo,此时需要写完整的模块名,即 import 后面那一串。
import aaa.bbb.ccc.xiashuo
# 需要写完整的模块名,即import后面那一串
print(aaa.bbb.ccc.xiashuo.name)
print("started")
输出:
aaa imported
bbb imported
ccc imported
i am imported
xiashuo
started
换一种写法,简单一点,不需要写那么长的模块名
from aaa.bbb.ccc import xiashuo
xiashuo.info()
输出
aaa imported
bbb imported
ccc imported
i am imported
xiashuo,12
还有一种写法,进一步省略模块名,但是就是比较容易出现明明覆盖,当然你可以重命名
from aaa.bbb.ccc.xiashuo import xia_shuo
print(xia_shuo())
输出
aaa imported
bbb imported
ccc imported
i am imported
xiashuo constructed
<aaa.bbb.ccc.xiashuo.xia_shuo object at 0x000001EED745A860>
现在来看引入包而不是模块的时候的现象,
import aaa.bbb.ccc
print(aaa.bbb.ccc.name)
输出
aaa imported
bbb imported
ccc imported
ccc package
还不明显
from aaa.bbb import ccc
# 增加符号 ccc
print(dir())
# 可直接通过ccc来调用
print(ccc.name)
输出
aaa imported
bbb imported
ccc imported
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'ccc']
ccc package
我们通过 import 命令引入 ccc 这个包,注意这是一个包,一个目录,不是一个模块,但是我们可以访问其 name 属性,而且这个 name 属性跟我们在 ccc 这个包的 __init__.py 文件中的一致,经过修改,再看结果我们可以肯定 ccc.name 访问的就是 __init__.py 文件中的 name,因此,我们可以得出结论:在 Python 中,包实际上会被识别为一个模块,包名就是模块名,这个模块对应的文件,就是此包下的 __init__.py。这也就解释了为什么目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包。这也解释了为什么引入包下的模块的时候,包路径下的 __init__.py 的文件中的脚本也会运行(因为包也是一个模块)。这也解释了另外一个容易混淆的概念,即,引入一个包之后,不会自动引入其子包,也就是不存在路径递归的效果:
from aaa import bbb
# module 'aaa.bbb' has no attribute 'ccc'
# 从这个报错信息中也可以看出, 包'aaa.bbb' 确实是被识别为了一个模块
print(bbb.ccc.name)
会报错,从报错信息中也可以验证我们之前说的,Python 确实是把 aaa.bbb 识别成了一个模块。我们可以以此推广,bbb 这个模块对应的模块文件 __init__.py 确实没有声明 ccc 这个变量,因此报错
bbb 会被识别为一个模块,而不会被识别为一个目录
from import *
from import * 我们在模块的 from import 小节中已经实践过了,
在 from 一个模块 import *,即 from modname import * 的时候,Python 不会导入模块中带有单个前置下划线的名称(除非模块定义了覆盖此行为的 __all__ 列表),但是依然会导入其他名称,此时我们可以在模块的代码中通过将想要被导入的变量都放到 __all__ 这个列表变量中,这样就可以覆盖默认的 import 行为,注意,此时的 __all__ 值都是模块内的名称符号。
而有了包之后,当我们 from 一个包 import *,即 from packagename import * 的时候,如果在 packagename 对应的 __init__.py 文件中没有定义 __all__ 变量,那么 from packagename import *不会导入包 packagename 里的任何子模块或者子包。这个语句等价于把 packagename 这个包当作一个模块把 packagename 对应的 __init__.py 导入了了当前模块,如果 packagename 定义文件 __init__.py 文件存在一个叫做 __all__ 的列表变量,那么在使用 from packagename import * 的时候就把这个列表中的所有名字作为包内容导入。此时 __init__.py 文件中的 __all__ 变量的值是当前包下的子包名称或者模块的名称,
配合我们在上一个小节中也说过,包实际上会被识别为一个模块,包名就是模块名,所以实际上,包中的子包名跟包下的模块名,是一个东西。
我们并不主张使用
*这种方法来导入模块
简单实践如下
设置 __all__ 变量:
修改一下 ccc 包下的 __init__.py
print("ccc imported")
# __all__ = ["xiashuo"]
name = 'ccc package'
执行代码
from aaa.bbb.ccc import *
# 把 aaa.bbb.ccc 当成一个模块来理解
print(name)
输出:
aaa imported
bbb imported
ccc imported
ccc package
设置 __all__ 变量:(将 ccc 模块的 __init__.py 中 __all__ 变量的注释放开)
因为 aaa 的 __init__.py 中 __all__ 变量的值为 bbb,因此 from aaa import * 的作用是导入了 bbb 这个子包,并将其当作一个模块来看待
因为 bbb 的 __init__.py 中 __all__ 变量的值为 ccc,因此 from aaa.bbb import * 的作用是导入了 ccc 这个子包,并将其当作一个模块来看待
from aaa.bbb import *
print(ccc.name)
输出:
aaa imported
bbb imported
ccc imported
ccc package
因为 ccc 的 __init__.py 中 __all__ 变量的值为 xiashuo,因此 from aaa.bbb.ccc import * 的作用是导入了 xiashuo 这个模块
from aaa.bbb.ccc import *
print(xiashuo.name)
print(xiashuo.age)
xiashuo.info()
输出:
aaa imported
bbb imported
ccc imported
i am imported
xiashuo
12
xiashuo,12
相对引入
. 表示当前目录,.. 表示上级目录,比如这种写法,from ..bbb.ccc import xiashuo,不能直接运行包含相对引入的代码,否则会报错
ImportError: attempted relative import with no known parent package
因为相对导入使用模块的 __name__ 属性来确定该模块在包层次结构中的位置。如果模块的名称不包含任何包信息 (例如,它被设置为 __main__),那么使用了相对导入的模块将被解析为顶级模块,而不管模块在文件系统中的实际位置。相对导入依赖于 __name__ 属性来确定当前模块在包层次结构中的位置。在 main 模块中,__name__ 属性的值总是 __main__,因此显式相对导入总是会失败 (因为它们只适用于包中的模块)。
解决方案:
-
执行的时候添加
-m参数,即python -m xxx.py -
设置
__package__属性 -
使用绝对引入和 setuptools
-
使用绝对引入和一些样板代码
重新加载
关于导入,还有一点非常关键:加载只在第一次导入时发生。这是 Python 特意设计的,因为加载是个代价高昂的操作。
通常情况下,如果模块没有被修改,这正是我们想要的行为;但如果我们修改了某个模块,重复导入不会重新加载该模块,从而无法起到更新模块的作用。有时候我们希望在 运行时(即不终止程序运行的同时),达到即时更新模块的目的,内建函数 reload() 提供了这种 重新加载 机制。
关键字 reload 与 import 不同:
import是语句,而reload是内建函数import使用 模块名,而reload使用 模块对象(即已被 import 语句成功导入的模块)
重新加载(reload(module))有以下几个特点:
- 会重新编译和执行模块文件中的顶层语句
- 会更新模块的名字空间(字典 M.dict):覆盖相同的名字(旧的有,新的也有),保留缺失的名字(旧的有,新的没有),添加新增的名字(旧的没有,新的有)
- 对于由
import M语句导入的模块 M:调用reload(M)后,M.x为 新模块 的属性 x(因为更新 M 后,会影响M.x的求值结果) - 对于由
from M import x语句导入的属性 x:调用reload(M)后,x仍然是 旧模块 的属性 x(因为更新 M 后,不会影响x的求值结果) - 如果在调用
reload(M)后,重新执行import M(或者from M import x)语句,那么M.x(或者x)为 新模块 的属性 x
包属性
我们前面看到的
__all__变量就是包属性
与模块相比,包的 固有属性 仅多了一个 __path__ 属性,其他属性完全一致(含义也类似)。
__path__ 属性即包的路径(列表),用于在导入该包的子包或子模块时作为搜索路径;修改一个包的 __path__ 属性可以扩展该包所能包含的子包或子模块
第三方包
我们知道,包可以包含一堆的 Python 模块,而每个模块又内含许多的功能。所以,我们可以认为:一个包,就是一堆同类型功能的集合体。
在 Python 程序的生态中,有许多非常多的第三方包(非 Python 官方),可以极大的帮助我们提高开发效率,如:
-
网络请求:Requests
-
科学计算中常用的:numpy 包
-
数据分析中常用的:pandas 包
-
大数据计算中常用的:pyspark、apache-flink 包
-
图形可视化常用的:matplotlib、pyecharts
-
人工智能常用的:tensorflow
这些第三方的包,极大的丰富了 Python 的生态,提高了开发效率。但是由于是第三方,所以 Python 没有内置,所以我们需要安装它们才可以导入使用。
通过 pip 这个包来安装其他第三方包
我们可以直接通过在 shell 中执行 pip install package_name 来下载 package_name 包,但是这会比较慢,通常我们可以指定国内的镜像 pip install -i mirror_url package_name 指定 pip 从国内的镜像中下载指定的包。一般国内镜像地址我们都选阿里云的 http://mirrors.aliyun.com/pypi/simple/,我们也可以将这个地址配置到 pip 的配置文件中,避免每次下载包都要手动输入一遍
关于 pip 的使用,请看《pip 配置文件.md》
在 Pycharm 中,我们可以在 Python Packages tool windos 中方便地搜索和下载第三方包,也可以在这里查看第三方的描述信息,非常方便。

通过搜索框右侧测小齿轮,我们可以配置包的下载地址,也就是 pip 配置文件中配置的地址,我们也可以将阿里云的地址配置在这里
此外如果自己电脑上有 SSR、Clash 之类的科学上网工具,也可以开启 Pycharm 的代理了,菜单地址为
Appearance & Behavior > System Settings > HTTP Proxy
目录结构规范
至此,我们已经了解了包和模块,现在可以变成工程代码了,为了写出规范的代码,有必要了解一下 Python 的目录结构规范
Pycharm 项目跟 IDEA 项目不一样的是,IDEA 中有工程和模块的区别,Pycharm 中只有工程,没有模块的概念
Python 项目也没有类似 Java 的 Maven 目录结构规范这种东西(从这里可以看出,Java 生态的完备),大家在 What is the best project structure for a Python application? - Stack Overflow 这个问题下广泛讨论,最终得出的是一个这样的规范目录:
假设工程名称为 Foo
```shell
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- init.py
| | |-- test_main.py
| |
| |-- init.py
| |-- main.py
|
|-- extras/
|
|-- dist/
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- pyproject.toml
|
|-- README
稍微解释一下:
> 参考: https://zhuanlan.zhihu.com/p/36221226
1. `bin/`: 存放项目的一些可执行文件,当然你可以起名 `script/` 之类的也行。
2. `foo/`: 存放项目的所有源代码。
- 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。
- 其子目录 `tests/` 存放单元测试代码;
- 程序的入口最好命名为 `main.py`。
3. `docs/`: 存放一些文档。
- `conf.py`:项目的配置文件,内容参考 [Python config file](https://martin-thoma.com/configuration-files-in-python/)
4. `extras/`: 有时候会使用到一些 C/C++ 库,一般放在这个文件夹里
5. `pyproject.toml`: 安装、部署、打包的脚本。由 [PEP 518 – Specifying Minimum Build System Requirements for Python Projects | peps.python.org](https://peps.python.org/pep-0518/) 引入,保存构建 Python 应用所需信息,这是一个比较新的标准,2016 年才开始使用,Setuptools 或者 Poetry 等打包工具可利用此文件将你的工程进行打包,然后发布,这样别人就可以通过 `pip install` 安装你的库.
> 大部分老项目会使用 `setup.py`,甚至很多教程让然推荐以 `setup.py` 编写打包过程,但是这已经不推荐了,建议换成 `pyproject.toml`
> 老项目会使用 `requirements.txt` 来管理依赖,`requirements.txt` 存放软件依赖的外部 Python 包列表。此文件可使用 pip 生成:`pip freeze >requirements.txt` ,当需要为项目的运行做好准备的时候,可以运行命令:`pip install -r requirements.txt`
>
> 使用 `pyproject.toml` 时,依赖不需要专门放到外面,放到 `pyproject.toml` 中统一进行管理
6. `dist/`: Setuptools 的打包结果存放路径,其实这个文件夹可以不手动建,Setuptools 工具会自动创建这个地址
7. `README`: 项目说明文件。
> 一些包管理工具可以根据自带的模板提供类似的结构,比如 Poetry,具体请看《Poetry- 打包和依赖管理.md》
其中,每一个模块的内容,最好是这样顺序编写:
- 模块的描述内容,注释
- import 语句
- 模块属性(模块内变量)定义,最好带有类型注解、注释
- 方法定义语句,最好带有类型注解、注释
- 类定义语句,最好带有类型注解、注释
- `if __name__ == '__main__':` 和其他可执行代码,最好带有类型注解、注释
因为没有统一规范,所以 Python 代码编写确实比 Java 要自由,你想怎么写都可以,但是这样的高灵活度如果没有规范约束,写出来的代码极有可能会乱七八糟,可读性差。
## 包的分发
包的分发包含两部分,一部分是打包,一部分的安装,关于安装,我们在 `第三方包` 小节已经学习过了怎么安装第三方包,接下来我们就应该了解如何打包。通过将 Python 项目打包,我们可以将其在任意 Python 环境钟安装,然后使用。
目前,主流的打包工具为 `setuptools`
> 具体操作请看《Setuptools- 打包.md》和《Poetry- 打包和依赖管理.md》